
Description
We have a K8s cluster with 3 servers and 3 pods (1 pod per server).
Weaviate has 20mln objects (2 named vectors per object: 1024 and 768).
All requests (set of CRUD+vectors-search operations) executed with QUORUM concistency level.
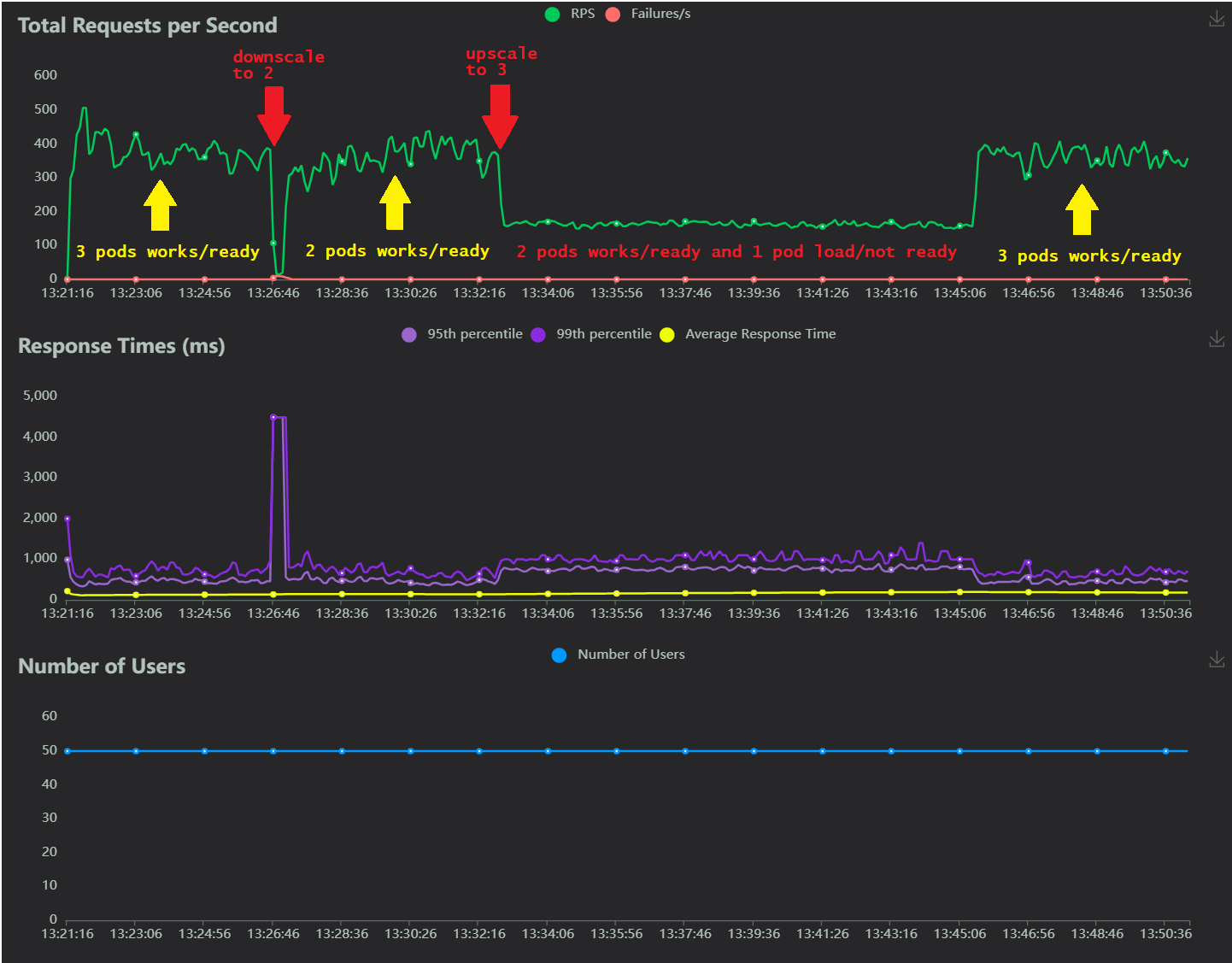
With 3 active (READY) pods we have a total performance with ~380RPS.
When downscaling cluster to 2 pods (“weaviate-2” goes away), cluster’s performance returns to same.
Upscaling cluster back to 3 pods (“weaviate-2” returns) make performance dropping to ~160RPS… on period while pod loading data/index (not in READY state).
Can’t see any CRUD/search requests in weaviate-2’s logs.
When “weaviate-2’s” loading finished (became READY), performance returns to normal ~380RPS.
Server Setup Information
- Weaviate Server Version: 1.25.25
- Deployment Method: k8s
- Multi Node? Number of Running Nodes: yes, 3 nodes, repl.factor=3
- Client Language and Version: Python-3, weaviate-client-4.6.2
- Multitenancy?: no
Any additional Information
DISABLE_LAZY_LOAD_SHARDS=true
HNSW_STARTUP_WAIT_FOR_VECTOR_CACHE=true