Description
It seems like weaviate have some kind of buffer corruption on search under parrallel write requests.
We have a service that is crusial for accuracy and recall for searching events and while high write requests Weaviate starts muss search results.
Each object in our Weaviate config has some key properties that we need to match after.
For example:
Search vector:
- key_id: 123456
- vector (some new generated vector through our model)
Search results without parallel requests:
"similars":[
{
"created":"2025-04-13T14:49:32.243000Z",
"id":"f7ed408c-cbde-4749-ac8e-96d0d8fc984b",
"key_id":"**123456**", # id same as we searched
"updated":"2025-04-13T14:49:32.243000Z",
"distance":**0.3067777156829834**
},
{
"created":"2025-01-30T13:51:27.624000Z",
"id":"5105ea9a-c9b6-4cc2-a044-e25b604729c7",
"key_id":"`567890`", # different id
"updated":"2025-01-30T13:51:27.624000Z",
"distance":`0.3187061548233032`
},
{
"created":"2025-01-30T10:01:03.661000Z",
"id":"16ec6bd3-d51e-4886-b9d5-d85a5bbf61f5",
"key_id":"~098765~", # another different id
"updated":"2025-01-30T10:01:03.661000Z",
"distance":~0.3222454786300659~
},
{
"created":"2025-05-21T02:23:41.679000Z",
"id":"de5d970f-461d-4765-a8ac-cb73a6b24f0a",
"key_id":"573211",
"updated":"2025-05-21T02:23:41.679000Z",
"distance":0.6350002288818359
}
]
Next I took the same vector that I used to search and got following results (correct):
"similars": [
{
"created": "2025-01-30T12:23:28.038000Z",
"id": "ab9957d5-8304-4099-9b4d-c47a71016c6c",
"key_id": "**123456**", # same key_id
"updated": "2025-01-30T12:23:28.038000Z",
"distance": **0.3067777156829834** # even the distance the same
},
{
"created": "2025-06-06T10:26:41.979000Z",
"id": "1d5e69d3-48ba-4f57-a612-0c7ca5790fbf",
"key_id": "**123456**", # now correct object
"updated": "2025-06-06T10:26:41.979000Z",
"distance": `0.3187061548233032` # the same distance as before BUT correct obj now
},
{
"created": "2025-04-13T14:49:32.243000Z",
"id": "f7ed408c-cbde-4749-ac8e-96d0d8fc984b",
"key_id": "**123456**", # again correct key_id
"updated": "2025-04-13T14:49:32.243000Z",
"distance": ~0.3222454786300659~ # and again the same distance with correct obj
},
{
"created": "2025-01-30T13:51:27.624000Z",
"id": "5105ea9a-c9b6-4cc2-a044-e25b604729c7",
"key_id": "`567890`", # obj key_id that was on 2nd place now on 4th with correct distance
"updated": "2025-01-30T13:51:27.624000Z",
"distance": 0.6350002288818359 # correct distance for obj "key_id": "`567890`"
}
]
So as you can see we expect the search results to be as the second search but when there are parallel write requests with search requests there are such kind of issues.
Please also mention that the distances while the search was correct and only objs itself was messed up!
Server Setup Information
- Weaviate Server Version: 1.29.4 (Also tested 1.25.27)
- Deployment Method: k8s
- Multi Node? Number of Running Nodes: 3
- Client Language and Version: python3.11 weaviate-client == 4.10.2
- Multitenancy?: no
Any additional Information
Firstly we think that it is a problem with async replication but the theory was not proved.
Here is the configuration that we are using
- name: ASYNC_REPLICATION_ALIVE_NODES_CHECKING_FREQUENCY
value: 5s
- name: ASYNC_REPLICATION_DIFF_BATCH_SIZE
value: '100'
- name: ASYNC_REPLICATION_DIFF_PER_NODE_TIMEOUT
value: 10s
- name: ASYNC_REPLICATION_DISABLED
value: 'false'
- name: ASYNC_REPLICATION_FREQUENCY
value: 5s
- name: ASYNC_REPLICATION_FREQUENCY_WHILE_PROPAGATING
value: 5s
- name: ASYNC_REPLICATION_HASHTREE_HEIGHT
value: '20'
- name: ASYNC_REPLICATION_LOGGING_FREQUENCY
value: 5s
- name: ASYNC_REPLICATION_PROPAGATION_BATCH_SIZE
value: '1000'
- name: ASYNC_REPLICATION_PROPAGATION_CONCURRENCY
value: '20'
- name: ASYNC_REPLICATION_PROPAGATION_DELAY
value: 30s
- name: ASYNC_REPLICATION_PROPAGATION_LIMIT
value: '1000000'
- name: ASYNC_REPLICATION_PROPAGATION_TIMEOUT
value: 30s
- name: DISABLE_TELEMETRY
value: 'true'
- name: TOMBSTONE_DELETION_CONCURRENCY
value: '4'
- name: GO_PROFILING_DISABLE
value: 'true'
- name: FORCE_FULL_REPLICAS_SEARCH
value: 'false'
- name: ASYNC_INDEXING
value: 'true'
- name: AUTOSCHEMA_ENABLED
value: 'false'
- name: CLUSTER_DATA_BIND_PORT
value: '7001'
- name: CLUSTER_GOSSIP_BIND_PORT
value: '7000'
- name: DISABLE_LAZY_LOAD_SHARDS
value: 'true'
- name: ENABLE_API_BASED_MODULES
value: 'false'
- name: PERSISTENCE_HNSW_MAX_LOG_SIZE
value: 16GiB
- name: QUERY_SLOW_LOG_ENABLED
value: 'false'
- name: QUERY_SLOW_LOG_THRESHOLD
value: 500ms
- name: RECOUNT_PROPERTIES_AT_STARTUP
value: 'false'
- name: GOGC
value: '85'
- name: GOMAXPROCS
value: '39'
- name: HNSW_STARTUP_WAIT_FOR_VECTOR_CACHE
value: 'true'
- name: LIMIT_RESOURCES
value: 'true'
- name: LOG_LEVEL
value: debug
- name: PROMETHEUS_MONITORING_ENABLED
value: 'true'
- name: PROMETHEUS_MONITORING_GROUP
value: 'true'
- name: QUERY_MAXIMUM_RESULTS
value: '1000'
- name: REINDEX_SET_TO_ROARINGSET_AT_STARTUP
value: 'true'
- name: REINDEX_VECTOR_DIMENSIONS_AT_STARTUP
value: 'false'
- name: STANDALONE_MODE
value: 'false'
- name: TRACK_VECTOR_DIMENSIONS
value: 'false'
- name: PERSISTENCE_DATA_PATH
value: /var/lib/weaviate
- name: PERSISTENCE_LSM_ACCESS_STRATEGY
value: pread
- name: DEFAULT_VECTORIZER_MODULE
value: none
- name: RAFT_BOOTSTRAP_TIMEOUT
value: '7200'
- name: RAFT_BOOTSTRAP_EXPECT
value: '3'
- name: RAFT_JOIN
value: weaviate-0,weaviate-1,weaviate-2
- name: RAFT_ENABLE_ONE_NODE_RECOVERY
value: 'false'
- name: RAFT_ENABLE_FQDN_RESOLVER
value: 'true'
Schema:
{
"class": "KeyClass",
"invertedIndexConfig": {
"bm25": {
"b": 0.75,
"k1": 1.2
},
"cleanupIntervalSeconds": 60,
"stopwords": {
"additions": null,
"preset": "en",
"removals": null
}
},
"multiTenancyConfig": {
"autoTenantActivation": false,
"autoTenantCreation": false,
"enabled": false
},
"properties": [
{
"dataType": [
"text"
],
"description": "key_id",
"indexFilterable": true,
"indexRangeFilters": false,
"indexSearchable": true,
"name": "key_id",
"tokenization": "word"
}
],
"replicationConfig": {
"asyncEnabled": false,
"deletionStrategy": "NoAutomatedResolution",
"factor": 3
},
"shardingConfig": {
"actualCount": 3,
"actualVirtualCount": 384,
"desiredCount": 3,
"desiredVirtualCount": 384,
"function": "murmur3",
"key": "_id",
"strategy": "hash",
"virtualPerPhysical": 128
},
"vectorIndexConfig": {
"bq": {
"enabled": false
},
"cleanupIntervalSeconds": 300,
"distance": "cosine",
"dynamicEfFactor": 8,
"dynamicEfMax": 500,
"dynamicEfMin": 100,
"ef": 640,
"efConstruction": 640,
"filterStrategy": "sweeping",
"flatSearchCutoff": 40000,
"maxConnections": 64,
"multivector": {
"aggregation": "maxSim",
"enabled": false
},
"pq": {
"bitCompression": false,
"centroids": 256,
"enabled": false,
"encoder": {
"distribution": "log-normal",
"type": "kmeans"
},
"segments": 0,
"trainingLimit": 100000
},
"skip": false,
"sq": {
"enabled": false,
"rescoreLimit": 20,
"trainingLimit": 100000
},
"vectorCacheMaxObjects": 1000000000000
},
"vectorIndexType": "hnsw",
"vectorizer": "none"
}
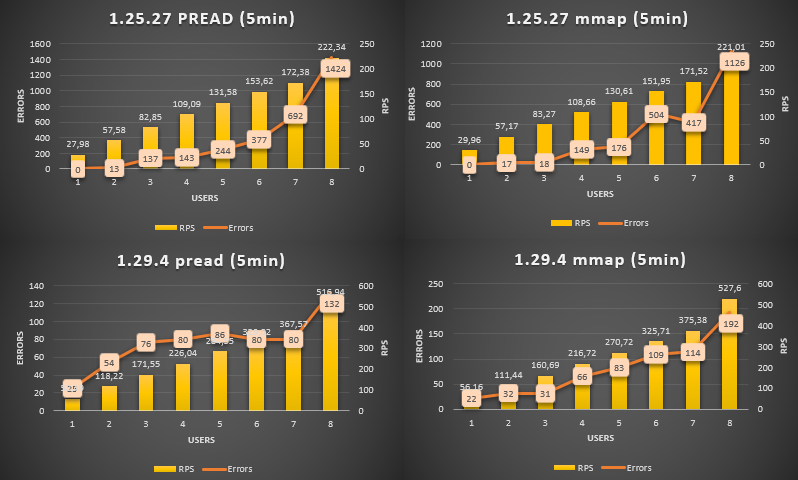
Also we measured number of appearing errors during load and there are some graphs